C语言深入探索之单链表与typedef的用法
前言
昨天博主去本站问答贴子逛了逛,然后发现了好多关于数据结构线性表,具体来说是单链表的问题。有的是没有一点思路,无从下手;有的是看不懂代码,不理解关键字以及被形参的形式气的不行,我总结了一下常见问题来给大家带来干货,到后面还有简单案例来巩固知识,弄透一题胜无脑刷百题,接下来是正文内容。
详解typedef关键字
含义
C语言允许用户使用 typedef 关键字来定义自己习惯的数据类型名称,来替代系统默认的基本类型名称、数组类型名称、指针类型名称与用户自定义的结构型名称、共用型名称、枚举型名称等。一旦用户在程序中定义了自己的数据类型名称,就可以在该程序中用自己的数据类型名称来定义变量的类型、数组的类型、指针变量的类型与函数的类型等。
具体使用
单链表结点示例:
typedef struct node
{
int data;//数据域
struct node * next;//指针域
}Lnode, * SLinkList;
这里我们创建了 node 结构体,结构体里面包含了 整型数据data,指针next 指向下一个结点的地址。可以看到下面大括号外有 Lnode和*SLinkList。他的意思就是我们给node 起了一个别名叫Lnode,Lnode具有和node相同的结构,struct node n1与Lnode n1 效果完全相同;同时C语言还允许在结构中包含指向它自己的指针,即 SLinkList L 等价于 struct node* L 或者 Lnode *L;
详解单链表参数形式
指针知识补充
示例:
//1、
int* getValue1(int *&L)
{
int a = 10;
L = &a;
return L;
}
//2、
int* getValue2(int *L)
{
int a = 10;
L = &a;
return L;
}
int main()
{
int* ptr = (int*)malloc(sizeof(int) * 4);
getValue1(ptr);
getValue2(ptr);
cout << *ptr << endl;
}
我在主函数中为指针ptr动态分配了内存空间,大小为4*4字节,不理解的可以参考我的这篇博文详解数据结构线性表里面的动态分布内存函数malloc;然后将地址传递到上面两个函数里面去,输出getValue1 的*ptr 结果是10,但是getValue2 中*ptr 的结果却是乱码。那么原因很明显,就是参数 int *&L和 int *L的区别了。这个函数的返回值是一个地址,然而在栈区开辟的数据,在函数调用结束后就会被编译器自动释放掉,从而返回的地址不会是&a,因此仅仅使用地址传递是不行的。那么加上&为什么就可以了呢,这是因为我们的目的是改变传入指针所指向的地址,第一种只能改变该地址对应的数值,第二种可以从本质上更改地址,所以能得到 &a 从而*ptr结果为10。
单链表形参详解
示例:
typedef struct node
{
int data;//数据域
struct node * next;//指针域
}Lnode, * SLinkList;
SLinkList Init_List(Lnode *&L)
{
L = (SLinkList)malloc(sizeof(Lnode));
L->next = NULL;
return L;
}
同样的,根据我前面讲的知识,我定义了一个SLinkList 指针型的初始化链表函数 Init_List(),传入的是结构体指针变量L,接下来为L分配内存空间,这里sizeof(Lnode)是计算了结构体Lnode所占内存大小并将此内存分配给L,接下来让初始化L,让其指针域为空。实际上L->data =NULL,L 就是单链表中的头结点。这段代码是没有问题的,但是如果把形参中的Lnode *&L,改为Lnode *L,那么编译器必然会提示我们,取消对NULL指针的使用,这就是为什么我们要加上&的原因,不加&返回的不是我们分配的指针变量L的地址,那这样我们的初始化毫无意义,虽然不报错,但是毫无作用。所以提醒你们写数据结构的时候记住这个小细节,很重要的!
单链表实战案例
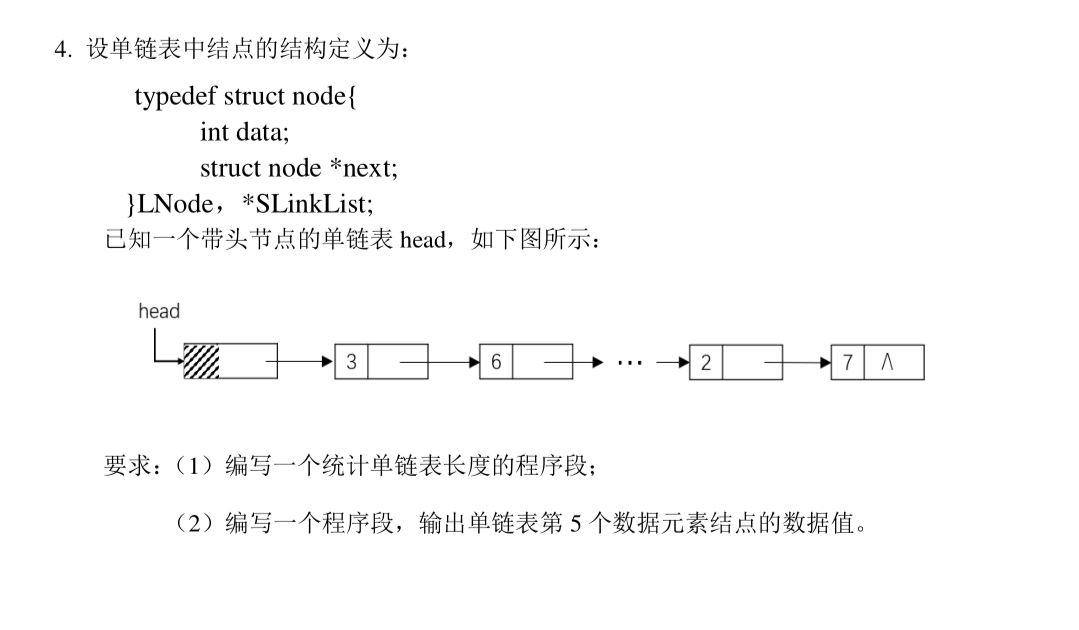
完整代码实现
#include<iostream>
using namespace std;
#define SIZE 10
typedef struct node
{
int data;//数据域
struct node * next;//指针域
}Lnode, * SLinkList;
SLinkList Init_List(Lnode *&L)
{
L = (SLinkList)malloc(sizeof(Lnode));
L->next = NULL;
return L;
}
SLinkList Creat_List(Lnode* &L,int n)//头插建表
{
srand((unsigned int)time(NULL));
SLinkList p = L;
for (int i = 0; i < n; i++)
{
int e = rand() % 20 + 1;
SLinkList s = (SLinkList)malloc(sizeof(Lnode));
s->next = p->next;
p->next = s;
s->data = e;
}
return L;
}
int count_List(Lnode *& L)
{
int count = 0;
SLinkList p = L->next;
while (p)
{
count++;
p = p->next;
}
return count;
}
int find_List(SLinkList L,int v)
{
SLinkList p = L->next;
int i = 1;
while (i < v && p->next)
{
p = p->next;
i++;
}
return p->data;
}
void display_List(SLinkList L)
{
SLinkList p = L->next;
while (p)
{
cout << p->data << " ";
p = p->next;
}
}
int main()
{
srand((unsigned int)time(NULL));
int n = rand()%5 + 5, count = 0, v = 0;
SLinkList L;
L = Init_List(L);
cout << "随机插入元素完成:"<<endl;
L = Creat_List(L,n);
count = count_List(L);
cout << "单链表长度为:" << count << endl;
cout << "遍历单链表结果为:" << endl;
display_List(L);
cout << endl;
cout << "要查找元素的位置为:"; cin >> v;
int value = find_List(L, v);
cout << "查找结果为:" << value << endl;
}
详解头插建表
把头插建表方法复制过来
SLinkList Creat_List(Lnode* &L,int n)//头插建表
{
srand((unsigned int)time(NULL));
SLinkList p = L;
for (int i = 0; i < n; i++)
{
int e = rand() % 20 + 1;
SLinkList s = (SLinkList)malloc(sizeof(Lnode));
s->next = p->next;
p->next = s;
s->data = e;
}
return L;
}
这里不用管srand((unsigned int)time(NULL));这段代码是为了产生不同随机数,和我讲的内容没有什么联系;往下看,创建建构体指针变量p并把p设置为头指针:L是头结点,p=L,p指向链表第一个带值结点。进入循环语句,循环语句n我会利用随机数产生;e是1~20范围内随机的一个数值,结构体指针变量s被动态分配内存空间s->next = p>next; p->next = s;s->data = e;这三行代码是头插法的核心。首先待插入原色s指针指向头结点指向的结点,然后头指针指向s,这样链表的链就连好了,最后给s的数据域赋值为e,执行循环语句,这样新插入的结点都会在上一个插入结点的前面,这就是头插法的全部过程。
int count_List(Lnode *& L); 方法对应第一问;
int find_List(SLinkList L,int v);方法对应第二问;
相信认真看完这篇博文的你可以很好理解上面两种方法的含义以及整个源码表达的意思,最后附上运行效果截图:
运行效果

关于C语言深入探索之单链表与typedef的用法的文章就介绍至此,更多相关C语言单链表与typedef内容请搜索编程宝库以前的文章,希望以后支持编程宝库!
前言计算机专业都逃不了数据结构这门课,而这门课无疑比较难理解,所以结合我所学知识,我准备对顺序表做一个详细的解答,为了避免代码过长,采用分文件编写的形式,不仅可以让代码干净利落还能提高代码可读 ...