Oracle递归查询connect by用法
一、概述
- Oracle中可以通过START WITH . . . CONNECT BY . . .子句来实现SQL的层次查询.
- 自从Oracle 9i开始,可以通过SYS_CONNECT_BY_PATH函数实现将父节点到当前行内容以“path”或者层次元素列表的形式显示出来。
- 自从Oracle 10g 中,还有其他更多关于层次查询的新特性 。例如,有的时候用户更关心的是每个层次分支中等级最低的内容。
那么你就可以利用伪列函数CONNECT_BY_ISLEAF来判断当前行是不是叶子。如果是叶子就会在伪列中显示“1”,
如果不是叶子而是一个分支(例如当前内容是其他行的父亲)就显示“0”。 - 在Oracle 10g 之前的版本中,如果在你的树中出现了环状循环(如一个孩子节点引用一个父亲节点),
Oracle 就会报出一个错误提示:“ ORA-01436: CONNECT BY loop in user data”。如果不删掉对父亲的引用就无法执行查询操作。
而在 Oracle 10g 中,只要指定“NOCYCLE”就可以进行任意的查询操作。与这个关键字相关的还有一个伪列——CONNECT_BY_ISCYCLE,
如果在当前行中引用了某个父亲节点的内容并在树中出现了循环,那么该行的伪列中就会显示“1”,否则就显示“0”。
1、层级查询的基本语法:
select [level],* feom table_name start with 条件1 connect by [ nocycle ] prior 条件2 where 条件3 ORDER BY [ sibilings ] 排序字段
说明:
- start with condition1 是用来限制第一层的数据,或者叫根节点数据;以这部分数据为基础来查找第二层数据,然后以第二层数据查找第三层数据以此类推。
- connect by [prior]id=parentid连接条件,目的就是给出父子之间的关系是什么,根据这个关系进行递归查询
- where 条件3---过滤条件,对所有返回的记录进行过滤。
- order by 排序字段---对所有返回记录进行排序
- 对prior说明:
- connect by prior dept_id=par_dept_id :采用自上而下的搜索方式(先找父节点然后找叶子节点),比如说查找第二层的数据时用第一层数据的id去跟表里面记录的parentid字段进行匹配,匹配成功那么查找出来的就是第二层数据;
- connect by dept_id=prior par_dept_id:采用自下而上的搜索方式(先找叶子节点然后找父节点)。 比如说用第一层数据的parentid去跟表记录里面的id进行匹配,匹配成功那么查找出来的就是第二层数据;
- level关键字,LEVEL---伪列,用于表示树的层次 ,第一层是数字1,第二层数字2,依次递增。
- CONNECT_BY_ROOT方法,能够获取第一层集结点结果集中的任意字段的值;例CONNECT_BY_ROOT(字段名)。
二、使用
1、基本用法
例1、 查询Raphaely及其的所有下属
select * from employees start with last_name = 'Raphaely' connect by prior employee_id = manager_id; --找下属 -- connect by employee_id = prior manager_id; --找上司,第一种,修改prior关键字位置 -- connect by prior manager_id = employee_id; --找上司,第二种,prior关键字不动 调换后面的 employee_id = manager_id 逻辑关系的顺序
例2、 查询除了Raphaely和他下属的所有员工
select * from employees start with manager_id is null connect by prior employee_id = manager_id and last_name <> 'Raphaely';
例3、 统计树形的层数
select count(distinct LEVEL) from EMPLOYEES start with MANAGER_ID is null connect by prior EMPLOYEE_ID = MANAGER_ID;
例4、 过滤某些结果集,注意:where子句比connect by后执行。
查询Kochhar的所有下属中lastname为 Mavris雇员。
SELECT * FROM employees WHERE last_name = 'Mavris' START WITH last_name = 'Kochhar' --Kochhar的所有雇员 CONNECT BY PRIOR employee_id = manager_id;
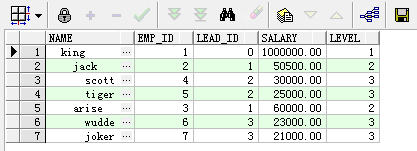
例5、level伪列的使用,格式化层级
select lpad(' ',level*2,' ')||emp_name as name,emp_id,manager_id,salary,level from employee
start with manager_id=0
connect by prior emp_id=manager_id
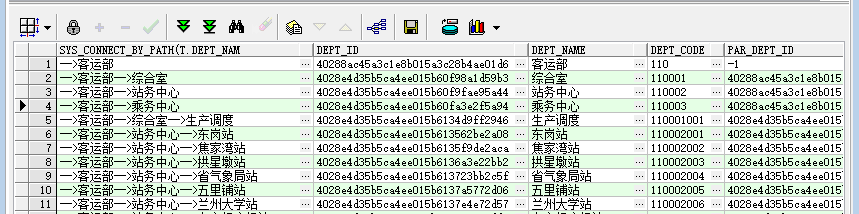
2、SYS_CONNECT_BY_PATH() 函数
作用: 将父节点到当前节点的路径按照指定的模式展现出来,把一个父节点下的所有节点通过某个字符区分,然后链接在一个列中显示。
格式:
sys_connect_by_path(<列名>,<连接串>)
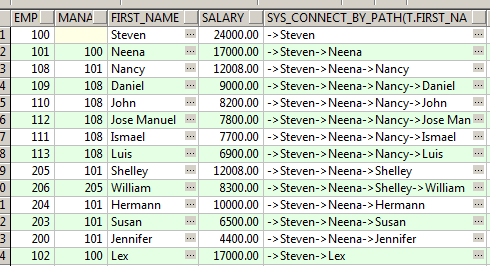
select sys_connect_by_path(t.dept_name,'-->'),t.dept_id, t.dept_name, t.dept_code,t.par_dept_id, level from SYS_DEPT t start with t.dept_id = 'e01d6' connect by prior t.dept_id = t.par_dept_id order by level, t.dept_code
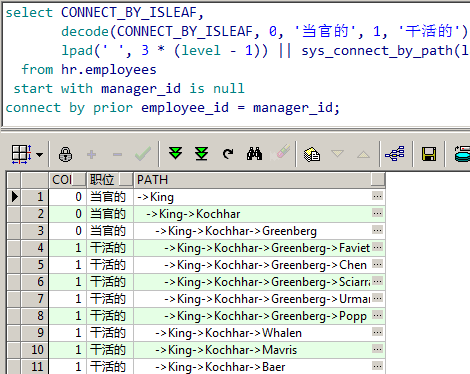
3、CONNECT_BY_ISLEAF 伪列
作用:判断层次查询结果集中的行是不是叶子节点
返回值: 0表示不是叶子节点, 1表示是叶子节点
例:
4、CONNECT_BY_ROOT 字段x -> 找到该节点最顶端节点的字段x
select last_name "Employee", connect_by_root last_name "Manager",sys_connect_by_path(last_name, ' -> ') "Path" from hr.employees
where level > 1
connect by prior employee_id = manager_id
order by last_name, length("Path");
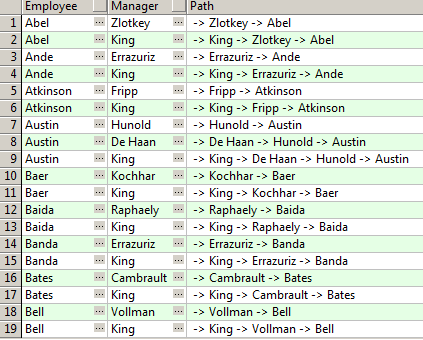
思考? 为什么不能加 start with ? 加了会有什么效果?
不加start with , 则每个节点都遍历一次 , connect_by_root 找到顶端的经理人会不同
而加了start with manager_id is null 则从树的根节点 King 开始遍历, 从而connect_by_root每个人的顶端的经理都是King
5、10g新特性 采用sibilings排序
作用: 因为使用order by排序会破坏层次,所以在oracle10g中,增加了siblings关键字的排序给叶子节点的关键字排序。
语法:
order siblings by <expre> asc|desc ;
它会保护层次,并且在每个等级中按expre排序
注意: order siblings by 必须紧跟着connect by,所以不能再用order by 了
例子:用order by,最后的结果是严格按照salary排序的,这样把层级关系都打乱了
select t.employee_id,t.manager_id,t.first_name,t.salary, sys_connect_by_path(t.first_name, '->'), level from hr.employees t start with manager_id is null connect by prior employee_id = manager_id order by salary desc;

采用sibilings排序:结果的树结构没有被打乱,且没层级的sibilings都是按照salary排序的。
select t.employee_id,t.manager_id,t.first_name,t.salary,sys_connect_by_path(t.first_name, '->'),level from hr.employees t start with manager_id is null connect by prior employee_id = manager_id order siblings by salary desc;
三、与row num 生成序列记录
rownum可用level代替。
1、简单序列:
select rownum from dual connect by rownum<=4
1
2
3
4
2、生成10-14的连续数(10开始,5行数据)
select 10+(rownum-1) from dual connect by rownum<=14-10+1
3、生成a-d的四个字母
select chr(ascii('a')+(rownum-1)) from dual connect by rownum<=ascii('d')-ascii('a')+1
4、生成2011-01-05至2011-01-10的日期
select to_date('2011-01-05','yyyy-mm-dd')+(rownum-1) from dual connect by rownum<=to_date('2011-01-10','yyyy-mm-dd')-to_date('2011-01-05','yyyy-mm-dd')+1
查询当前时间往前的12周的开始时间、结束时间、第多少周
select sysdate - (to_number(to_char(sysdate - 1, 'd')) - 1) - (rownum - 1) * 7 as startDate,
sysdate + (7 - to_number(to_char(sysdate - 1, 'd'))) - (rownum - 1) * 7 as endDate,
to_number(to_char(sysdate, 'iw')) - rownum + 1 as weekIndex
from dual
connect by level<= 12;--将level改成rownum可以实现同样的效果

- d 表示一星期中的第几天
- iw 表示一年中的第几周
5、字符串分割,由一行变为多行。
生成a1,b1,d1序列
select substr(id,
instr(id,',',1,rownum)+1,
instr(id,',',1,rownum+1) - instr(id,',',1,rownum)-1)--根据逗号的位置进行拆分
from (select ','||'a1,b1,d1'||',' as id from dual) --前后各加一个逗号
connect by rownum<=length(id)-length(replace(id,',',''))-1
或者
select REGEXP_SUBSTR('a1,b1,d1', '[^,]+', 1, rownum) as newport
from dual connect by rownum <= REGEXP_COUNT('a1,b1,d1', '[^,]+');
6、利用with子句生成测试数据
with temp as (select 'a' as A,'b' as B from dual union select 'c' as C,'d' as D from dual ) select * from temp;
7、日期维度数据生成方法。
select to_date('2011-01-05','yyyy-mm-dd')+(rownum-1) as ydate_date,
to_char(to_date('2011-01-05','yyyy-mm-dd')+(rownum-1),'yyyy') as ydate_month
from dba.tab_cols where to_date('2011-01-05','yyyy-mm-dd')+(rownum-1) != to_date('2060-01-05','yyyy-mm-dd')
关于Oracle递归查询connect by的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持编程宝库。
一、数值函数1、mod(n1,n2):n1除以n2的余数。如果n2为0,则返回n1。select mod(23,8),mod(24,8) from dual;--返回:7,02、power(n1,n2) ...